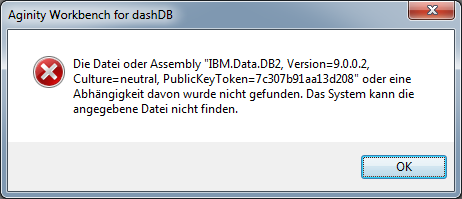
while iam trying to reach a cloud instance as db-tier, called dashDB, some side effect of the toolset here, is excentrical and need to be named…i tried with aqua data studio, but that failed as well, while java-8 is working under the hood and that 8 versions from times ago and now, wont play together :/
datastudio with half set home path for that vendor … crashed … oracle – make my day again …agenity, some proposed query workbench wont work with the current cloud instance…? tells me something about a version, i want dasdb, he means db2v9.0.0.2 – but where to put that driverclass then ?
meanwhile, i have found some equivalent to such tools, called „aginity workbench for dasndb„, also a eclipse based tool.
what to to, when a dude smashes a harddrive from a mac? the new drive dosnt have a clue about the ingredients of the machine, the firmware/bios is like a sissy to not let the owner accessing the system. several ways to get into the mac osx, but over the years, the rules went harder and one should explain the story to the support at some point.
top view
apple puts a lot of energy into their politics, to seal the borders of that system and to save the mac from other influences, except theirselfs. icloud is nowadays a default package, the most services, like imessage, is backed up in the cloud. no way to use such devices without such id for that storage and control of puzzlepiece. the mac is locked until the code of consumption is entered or penalty is payed to apples money-machine via customer care. fucking with assemblercode, to tweak the bios with u/efi and all that shit, is not even a plan. the firmware to restart the system is hidden within some hashes from the mainboard and the password itself, reverse engineering was not my plan for today.
ready or not, depends on the configuration of buttons and lights. this picture indicates a working chip.
if the mac is hanging on the four number code, to get back to live, one could call the customer care to get a scbo file or try typing the nearly 9999 combinations by hand. others are lazy to do so, a small processor, based on arm with 64kb ram, can do the same, much more gently. the tinypcb ( printed circuit board ) with a size of 35 x 17mm holds a usb-connector, the cpu with 256kb rom and a lot of connectors to participate with others.
the firmware tells its a v.1.03, flashed with the customized arduinoide ( integrated desktop enviroment { development tool } ) within seconds on the freescaleMK20DX256, but with some difficulties. arduino is not just a misswritten word, they could be seen as major pusher behind that uprising developer-board-scene. that teensy is a clon in some way, but in fact, arm or atmel had a product line over the past years, so one can find several configurations, sources and dealerprices, to get into the rush of diy, for a fistful flies. another eclipse plugin should be named, but i had so-so results on the download site, all files were incomplete, i guess the traffic limit is taken, on the end of the month. the project should move to the next level then.
update cycle finished
as i hadnt much experience with avr/atmel chips at all, i decided, to put everything in a virtual box, on windows 7 for some reasons. but suprise suprise, the winavr-toolkit wants to lay inside the default folder ( ${winDrive/winavr } ) instead of being sorted with others in the standard folder for program files (x86). anyhow, the masterpiece of microsoft is, that the usb port and parameter is buffered/saved within the registry and due to other lacks of their understanding of software design, the programer wont flash the hex.code from the arduino software into the chip. excellent, couple of hours later i gave up on this, as i wanted to use eclipse for larger developments.
so, burning the working code to the chip was only possible, with a direct connect to the host-system. some years ago, i played with a atmega ( think was …32 ) for a laser-tester, that one had started with basic-code. the arduino enviroment has its own syntax and file-extension.ino and with gnu, c/c++ software the architecture could be cascaded.
upgrade sucessfullly, the new code is flashed to the soc
so, the chip is now ready to stupidly check each number, from 0000->9999 until the mac agrees to work again, when the correct passcode is clearly analyzed, by try& error. oh yeah, the soc could do much more then this, but the case was just there, to check the stuff with a goal to reach. some dozen projects and use-cases for that little machine is visible on the web: dj-controller, measurement boxes with lcd displays or game-engines are out there and many other ideas are just eyeblinks away.
bigger or larger projects will clearly need some more attention and notes to be realized, but with a sd-card-slot in dollar-distance, the bugs for a unique or genuine solution is definitly no high steak or far away. things can be made and grown with developer kits, analog or digital interfaces, up to the samplerate of a oscilloscope or analyzer by mean.
ready or not, depends on the usb connection and windows is a sissy in that area, after 15 years of existance, a unhappy programmer with no chance to pump new bytes into the chip.
da festplatten zwar immer günstiger und größer werden, die dateien und formate aber auch, bleibt das ewige spiel mit dembackup. wie möchte man eine 2-3-4 terabyte platte sichern? wie kann man 10 oder 20TB sinnvoll wegschaufeln? was tun, wenn das haus abgebrannt oder abgesoffen ist – was ist dann mit den eigenen daten. klar, man kann sie brennen oder auf usb kopieren, aber ab einer bestimmten größe macht das alles keinen spass mehr. nun hab ich heut beim g+ ein paar interessante beispiel für verfügbare clouds aufgeschnappt:
tarsnap fällt durch schlichte leistung und geringe kosten auf. 0.30us$/gb-monat für den space und 0.30us$/gb beim traffic scheinen günstig zu sein. der wesentliche punkt aber ist, dass nur veränderte daten hochgeladen werden, ein inkrementelles backup sinngemäß. aes-256 wird angeboten und kann, da linux-basierter-client, durch eigene maßnahmen ergänzt werden. als infrastruktur wird amazon ec2 verwendet, also nichts aufregendes.
crashplan sieht wesentlich ausgereifter und professioneller aus. die verschlüsselung beträgt 448-bit für die dateien und 128bit-aes für die verbindung. 4us$ für einen rechner, total-backup, klingt ok – eine konkrete größe vermisse ich aber dann doch. für firmenkunden werden auch pakete mit 200 oder 1000 und mehr angeboten. die infrasturktur ist nicht auf den ersten blick ausgeschildert.
der vollständigkeithalber wären noch die üblichen verdächtigen zu nennen:
klar kann man sich auch ein nas hinstellen, doch es geht ja um ein offsite-backup, also eine sicherungskopie ausserhalb der eigenen vier wände. sicher, im bunker, tief im rechenzentrum, dupliziert, verteilt, gespiegelt – einfach bombensicher *hust*. was die einzelnen betreiber jedoch im kleingedruckten für regeln und leistungen haben, muss man dann doch genauer evaluieren.
ich bin jetzt doch n bisschen fickrig geworden auf son kleines scheißboard. da ich ohne rootserver und ohne linux kaum an der eisenbahnplatte ( cloud ) weiter schrauben kann, begeb ich mich auf der suche im netz zu einem versand in de_DE.
entweder ich bin zu aufgeregt, zu unkondensiert oder warum auch immer, ich übersehe, dass die erste generation nur single-core ist, 1 gb ram hat und die netzwerkkarte nur 10/100 mbit/s schafft. egal, für 50€ bin ich ja im budget des raspberry, aber mit doppelt so viel ram UND einem s-ata anschluss. das genügt mir als entschädigung. als ich das cubieboard in betrieb nehme.
cubieboard connected with sata hdd
auf der suche nach dokumentation, manuals, handbüchern – überhaupt irgendwelchen nützlichen informationen finde ich dann nach einigem suchen auch ein paar images, sie sich für sd-card eignen. ausserdem noch ein passendes „brenn-programm“ was die images da drauf tut. dabei fällt mir auch das ein oder andere image für den onboard-nand in die hände. ich saug erstmal was ich finde und probiere die verschiedenen ubuntu/debian/android versionen sukzessiv aus. einige booten garnicht, andere sind in zig versionen vorhanden – welche nehmen?
also bleibt mir wohl nichts übrig, als die verschiedenen konfigurationen zu checken. im wesentlichen schaue ich auf den treiber für die grafik einheit, also die gpu. dort ist eine mali-gpu verbaut, die direkt von arm stammt. das passenste triebwerk heißt „sunxi“ und ist direkt vom hersteller. die cpu, also der system-on-a-chip ( soc ) ist von ( ehemals allwinnertech ) nun unter http://cubieboard.org/model/ erreichbar und was dass heißt,mal schauen.. der schafft wohl 1080p, wie da im datenblatt steht – fragt sich nur mit wieviel frames pro sekunde :p
toll, warum hab ich die letzten monate bei den fights der x-server/clients nicht aufgepasst. mir, wayland, mesa, x11 … man was es da nun alles für zeug gibt. und wie zum henker wuppt man den treiber jetzt in den kernel :/ ich glaub, die frage krieg ich so schnell nicht beantwortet, daher krampf ich nicht weiter rum und mach mit config und install weiter.
einige versuche später bin ich noch nicht klüger, ich weiß zwar jetzt welche pakete so halbwegs laufen und wie man mit dem speicher haushaltet, frisch gebootet verbraucht das ding 80 mb mit xfce dann 180. ist der browser offen, sinds so um die 280 gb. tomcat läuft schon im hintergrund, oracles java ist auch drauf, nur die grafik ruckelt wie sau. von dem gigabyte ram sind 808 mb verfügbar, da bleibt noch ein bisschen luft für arbeitsdaten. jedoch noch kein open.gl, kein videostreaming, kein garnix in der richtung. die cpu auf vollanschlag kotzt, doch der treiber ist wohl noch immer nicht im kernel. muss ich mich jetzt wohl direkt mehr mit beschäftigen…..
cubieboard 1 in plexiglas behausung
tolle wurst, auf der einen seite lockt das ding mit kapazitäten, die eigentlich als settop-box ausreichen sollten und mir das video auf den fernseher streamt, auf der anderen seite könnte ich mir ein mini-nas bauen, da die sata-schnittstelle sowie drei usb anschlüsse platz für erweiterung lassen. aber ohne anständigen grafik-treiber, wirds wohl erstmal nix mit dem streaming-client. nuja, als load-balancer sollte der dampf wohl ausreichen, um die 100 mbit/s zu sätigen. übliche einstiegs-firewall-systeme haben auch nicht mehr und dsl oder vdsl ist derzeit auch nicht wesentlich schneller.
für escii hab ich da grad owncloud installiert. eher durch zufall fiel mir das auf, als ich die verfügbaren softwarepakete bei seinem provider durchsah. also klick-klack gleich mal installiert.
owncloud ist php-basiert und läuft auf nur einer maschine und ist damit nicht wirklich „cloud“ … klingt aber trotzdem toll. es gibt eine community und eine professionell version. die kostenlose v5 hab ich dann gleich mal drauf getan und es lief auf anhieb.
flux ein paar benutzer eingerichtet, plugins nachgeladen und die ersten samples mit ihm geshared. ging alles relativ flott und auch via webdav auf mobilen geräten recht flüssig. bei vielen benutzern kommt jedoch einiges an traffic zusammen, wenn man seine arbeitsverzeichnisse/repositories darüber synchronisieren will. aber für den augenblick war das 1 gigabyte webspace ausgenutzt. also den uralten vertrag beim provider aktualisiert und schon 10 gb gehabt. damit kann er wohl erstmal ne weile leben und brauch keine one-click-hoster mehr, wenn er seine mukke ( tracks oder mixe ) mit anderen teilen möchte.
um die arbeiten an der cloud auch ein wenig dokumentiert zu haben, hab ich das single-page-design noch einmal verwendet und für die konzeptuelle beschreibung online gestellt.
das konzept, welches sehr grob und auch ein bisschen vage oder schwammig die vorstellungen von der private cloud skizziert, beschäftigt sich mit den verschieden modulen. diese sind vorläufig mit
1. frontend
2. backend/datamodell
3. cluster
4. mechanics
5. cdn
umrissen. das frontend soll schlank sein und möglichst in einem rutsch, in einer datei ausgeliefert werden. da dynamische anfragen an die cloud möglichst minimal gehalten werden sollen, ist die anlieferung der inhalte – wenn statisch – dann durch einige cache-layer abgefedert. da die dateien auf verschiedenen knoten verteilt sind, kann es bei ungecachten dateien durchaus 2-3 sekunden dauern, bis diese verfügbar sind. ein prefetch oder precache ist daher sinnvoll. die dynamischen inhalten werden durch ein nosqlschema realisiert. das datenmodell ist in verschiedenen schichten sowohl im front- als auch im backend nutzbar und ist teilweise durch generische klassen oder reflektive methoden ergänzt. die dateiablage kann man als flatfile ansehen, die durch map-reduce-aufbau oder ein denormalisiertes modell gekennzeichnet ist.
was heute cloud heißt, war vorher ein cluster, davor ein grid und irgendwann bestimmt auch mal ein mainframe 🙂 die heut noch üblichen architekturen, mit application-server <-> database-server, network-attached-storage und ftp-backup wird verglichen mit dem konzept, welches meiner entwicklung zu grunde liegt. die skalierung von 6-10 maschinen ist dort skizziert, die 5.000 maschinen, die bei hadoop-clustern durchaus üblich sind, muss sich der geneigte leser dann vorerst doch noch vorstellen.
der workflow oder die sequenzen, die für die arbeit zwischen den layern benötigt wird, kann man als mechanik in diagrammen aufzeigen, so können für verschiedene anwendungszenarien die beteiligten komponenten identifiziert, beschrieben und ausgebaut werden. da alles in einer sprache verfasst ist, ist ein medienbruch oder andere dialekte vorerst nicht nötig.
ist die orchestration dann über verschiedene kontinente und mehrere rechenzentren verteilt, so können funktionen eines cdn implementiert werden. dort werden dann ungesehener und gesehener inhalt ausgetauscht, statistiken für die optimierung und auswertung angelegt und die günstigsten, schnellsten oder besten routen für die anlieferung der daten gewählt.
mit dieser infrastruktur kann dann auch streaming betrieben werden, da die signallaufzeiten und die kapazitäten den anforderungen des marktes angepasst sind und entsprechend flexibel dimensionierbar sind.
as a friend from a provider in berlin gave me the access to a vhost he had, i received another donation from him. a vhost instances with some more ram, as i had on the machine since now was now in the park.
so i had three machines to build my cloud further. since 2010 i was working with big-data tools and the hadoop-framework, a distributed file-system was the main aspect to build such thing. with the new server, i was able to raise the replication from 1 to 2. that was not the replication-factor of 3, which could be seen as minimum for hot-fail-over redundancy systems, but on the right way.
i introduced the machine to the cluster and configured the redirect-proxy the same way, as the machine in jena. after some tests, i had failures with „to many open files“ and i noticed, that the vhost-guest-system was heated to much with the hdfs, so i configured them further.
beside the cluster, i was able to use them as streaming-server for the radio as well, as i switched chromanova.fm on, with two channels as well. that was nice, to have capacity in bandwith that way and the scale was nearly linear to the count of machines.
now i was able to play harder with the layer between the tomcat-servlet and the byte-stream, given by the filesystem. the new machine had 4 gigabytes of ram and i gained the headroom for the caching on tomcat much higher then possible before.
as i had the wish to play with more then one server, i felt the need to configure the domain-name-service ( dns ) much more, then before.
my provider, where the usual webspace resides gave me access to the dns-infrastructure he had. that was cute, as i wasnt a reseller by fact and the need to maintain such things where another level of hosting configuration.
with that tool, to register a-records within the dns, i was able to build the cluster to cloud, with the ability to handle different sites for the different machines/server. i played with cdn.ioioioio.eu and other subdomains as the dataflow where handed-over between different services. several services were to handled by ip-addresses before, now i made that more niceley with names. that was a big step toward the idea of a cloud as the complexity was raising with each service and each instance.
the amount of subdomains and service-aliases raised quickly and i reduced them as i i wanted to keep the overview over the different things, that were hidden behind that curtain.