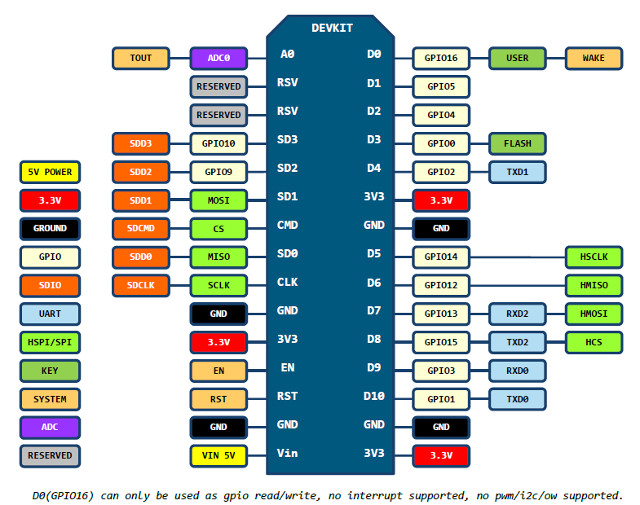
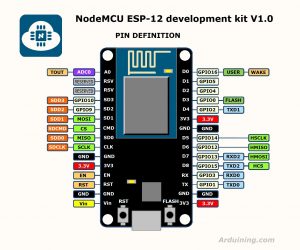
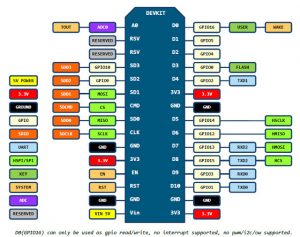
having such small device, with wifi and many analog and digital i/o ports by hand, is somehow nice. that general purpose input output connectors are known as GPIO….. the loveley mr. wang from hongkong, tower 4, building c had send me that esp8266 v3 (340) board within the second week, directly from china, by airmail.
device ports with addresses
that device ( nowerdays called „iot device“ ) can be used as serial bridge, for incomming / outgoing signals. a little more sophisticated is the idea, to send all the data by http with tcp/ip or as udp paket. a lot of traffic can be estimated, beside failure correction , missing paket and other crapy errors, that are common.
pushing a json string that way, triggered, when the value changes, could be more gentle to the chip. the unknown state of the receiver is the pitfall there. using websockets on the nodemcu will work with some message client, like mqtt, is the next climbing. the client subscribes to a master ( tomcat / rabbit mq or pure servlet with extras ) and delivers the information straight there. the server will handshake the request with a response, directly to a open port, on the client ip.
should be all, will see, when the code is working as expected. 20 sensors with 50 samples/second could mean 1000 requests per second – commonly. if nodemcu/raspberrypi3 is able to feature all that, is the question for the comming days. the arduino is something one have to learn, how to use that efficiently is the first step. the next is, to have some java ide, like eclipse ready with java, then tomcat and a dbms or storage engine, like mariadb installed within a virtual machine, with the same debian, that is used for raspberrypi, that is called raspian. then the code delivery or the binaries should work on both enviroments, even if the architecture will differ between amd and arm.
jvm settings, for partly tuning of garbace collection and memory allocation in general
zooOOOooomed
yes steve, i want porn
device ports with addresses
<code>
-Xms384m // headroom for memory to be free
-Xmx768m // all in all memory, to be recycled
-Xmn2m // stacksize for heap to 2mb
-XX:+UseG1GC // specific gc
-XX:MaxGCPauseMillis=75 // max timeout in ms.
-XX:NewRatio=2 // ratio between new and recycled obj
-XX:SurvivorRatio=4 // ratio for memory to reused
-XX:MaxNewSize=256m // max size for new objects
-XX:MaxPermSize=256m // permanent max. heap space
-XX:+UseStringCache // stringbuilder at its best
-Xloggc:..\eclipse.logfile.dump.txt // to external
what to to, when a dude smashes a harddrive from a mac? the new drive dosnt have a clue about the ingredients of the machine, the firmware/bios is like a sissy to not let the owner accessing the system. several ways to get into the mac osx, but over the years, the rules went harder and one should explain the story to the support at some point.
top view
apple puts a lot of energy into their politics, to seal the borders of that system and to save the mac from other influences, except theirselfs. icloud is nowadays a default package, the most services, like imessage, is backed up in the cloud. no way to use such devices without such id for that storage and control of puzzlepiece. the mac is locked until the code of consumption is entered or penalty is payed to apples money-machine via customer care. fucking with assemblercode, to tweak the bios with u/efi and all that shit, is not even a plan. the firmware to restart the system is hidden within some hashes from the mainboard and the password itself, reverse engineering was not my plan for today.
ready or not, depends on the configuration of buttons and lights. this picture indicates a working chip.
if the mac is hanging on the four number code, to get back to live, one could call the customer care to get a scbo file or try typing the nearly 9999 combinations by hand. others are lazy to do so, a small processor, based on arm with 64kb ram, can do the same, much more gently. the tinypcb ( printed circuit board ) with a size of 35 x 17mm holds a usb-connector, the cpu with 256kb rom and a lot of connectors to participate with others.
the firmware tells its a v.1.03, flashed with the customized arduinoide ( integrated desktop enviroment { development tool } ) within seconds on the freescaleMK20DX256, but with some difficulties. arduino is not just a misswritten word, they could be seen as major pusher behind that uprising developer-board-scene. that teensy is a clon in some way, but in fact, arm or atmel had a product line over the past years, so one can find several configurations, sources and dealerprices, to get into the rush of diy, for a fistful flies. another eclipse plugin should be named, but i had so-so results on the download site, all files were incomplete, i guess the traffic limit is taken, on the end of the month. the project should move to the next level then.
update cycle finished
as i hadnt much experience with avr/atmel chips at all, i decided, to put everything in a virtual box, on windows 7 for some reasons. but suprise suprise, the winavr-toolkit wants to lay inside the default folder ( ${winDrive/winavr } ) instead of being sorted with others in the standard folder for program files (x86). anyhow, the masterpiece of microsoft is, that the usb port and parameter is buffered/saved within the registry and due to other lacks of their understanding of software design, the programer wont flash the hex.code from the arduino software into the chip. excellent, couple of hours later i gave up on this, as i wanted to use eclipse for larger developments.
so, burning the working code to the chip was only possible, with a direct connect to the host-system. some years ago, i played with a atmega ( think was …32 ) for a laser-tester, that one had started with basic-code. the arduino enviroment has its own syntax and file-extension.ino and with gnu, c/c++ software the architecture could be cascaded.
upgrade sucessfullly, the new code is flashed to the soc
so, the chip is now ready to stupidly check each number, from 0000->9999 until the mac agrees to work again, when the correct passcode is clearly analyzed, by try& error. oh yeah, the soc could do much more then this, but the case was just there, to check the stuff with a goal to reach. some dozen projects and use-cases for that little machine is visible on the web: dj-controller, measurement boxes with lcd displays or game-engines are out there and many other ideas are just eyeblinks away.
bigger or larger projects will clearly need some more attention and notes to be realized, but with a sd-card-slot in dollar-distance, the bugs for a unique or genuine solution is definitly no high steak or far away. things can be made and grown with developer kits, analog or digital interfaces, up to the samplerate of a oscilloscope or analyzer by mean.
ready or not, depends on the usb connection and windows is a sissy in that area, after 15 years of existance, a unhappy programmer with no chance to pump new bytes into the chip.
unter homezone.ioioioio.eu ist mein heimrechner als weiterleitung erreichbar. da ich aktuell keinen root-server habe, ist das die möglichkeit, weiterhin präsentabel zu sein.
die kleine box ( cubieboard / cubietruck ) ist ein arm.v7 basierter server, auf dem ein tomcat–servlet-container läuft. da die ip sich bei dsl ändert, muss die aktualisierung eben auch häufiger erfolgen.das hab ich mit einem bash-shell-script erreicht, welches die weiterleitung auf dem webserver arrangiert.
screenshot – homezone.ioioioio.eu
mit ein paar schritten wird dazu eine index.html erstellt die per ftp auf den webserver hochgeladen wird. per cron-job wird alle zehn minuten nach der externen ip gefragt und bei änderung dann die geänderte datei hochgeladen. ist der server nicht erreichbar soll die weiterleitung aufgehoben sein und die index.html entsprechend verändert sein. jedenfalls soll eine statische html datei ausgeliefert werden, um möglichst performant zu sein und anfragen nicht durch prozessing zu behindern.
update.external.ip.sh
<code>
index.html
<code>
checkMetaData.php
<code>
so ganz rund sind die einzelnen schritte noch nicht, gehen aber in die richtige richtung. da auf dem webserver nur php verfügbar ist und ich da kein spezi bin, soll das ganze mit so wenig wie möglich php-code auskommen. es zeigt sich jedoch, das auf beiden seiten einiges an logic eingebaut sein muss und der workflow doch ein wenig defiziler ist, als ursprünglich gedacht. da zwischen homezone und rechenzentrum eine bidirektionale verbindung etabliert sein muss, prüft jede seite ein paar vorgaben, bevor der connect zu standen kommt. der ablauf ist in etwa wie folgt:
ist die html datei bereit ( deployed ) ist die mechanic etwa:
homezone online -> redirect via meta tag
homezone offline -> status/info ablesbar
logged in on homezone.ioioioio.eu
so ist die homezone auch von unterwegs für mich erreichbar und meine dort verfügbaren dateien nutzbar. noch nicht ganz knitterfrei, aber so langsam fällt mir auf, wo die haken und ösen hingehören. ist man eingelogged, kann man dateien in seinen account laden, sich roh-texte per map-reduce in javascript auf keywords filtern und technische daten zur verbindung einsehen. durch das hin&her von windows auf den root-server unter linux ist die listung der datei grad nicht okay, es wird schlicht im falschen verzeichnis geschaut. warum dann aber ausgerechnet quelltext zu sehen ist, muss ich wohl auch noch recherchieren. kalt geprüft braucht der server in diesem fall 63ms für den roundtrip, nach dem cache-warming geht die runde dann mit 13ms zu absolvieren. hier lohnt der vergleich zum entwicklungsrechner, der schafft auch grad mal 3-4-5 ms. für die gleiche nummer, durchaus akzeptabel für den kleinen kerl ( arm cortex a8 als allwinner a10 ).
da ich mir vor ein paar jahren ( 2008 / 2009 ) das google-web-toolkit
( gwt ) angeschaut und für gut befunden habe, taucht es hier in diesem kontext ebenso auf. der anfang war zäh, kompilieren auf kommanoZeile, die unterstützung für eclipse nur rudimentär. mittlerweile sind wir bei v.2.6.1 angelangt und eclipse ist bei 4.3 und heißt kepler, doch das ist ein anderes thema.
da ich unter linux und windows entwickel ( ja auch windows ist in der nutzung – schande hin oder her ) und gwt unmengen an temporären dateien erzeugt und mir die platte vollrotzt. warum windows das nach über 20 jahren immer noch nicht kann, ist mir ein rätsel.
ziel soll es sein, das die im eclipse ( aus java dateien erzeugten javascript-dateien ) generierten dateien und verzeichnisse unter windows gelöscht werden. in der praxis hat sich gezeigt, das bei jeder kompilierung ein paar dutzend megabyte anfallen, die sich im laufe einer session dann gern mal zu ein paar gigabytes summieren.
script1: startet eclipse und script 2 im hintergrund
<code>
script2: startet alle 10 minuten script 3 im hintergrund
<code>
script3: listet in drei verzeichnissen die dateien und löscht diese
<code>
da man sicher einiges noch schicker machen kann, kann es passieren, dass die scripte aktualisiert werden. so ganz rund wie gedacht, laufen sie leider noch nicht, auch wenn der reinemache-dienst nun tut.
um die arbeiten an der cloud auch ein wenig dokumentiert zu haben, hab ich das single-page-design noch einmal verwendet und für die konzeptuelle beschreibung online gestellt.
das konzept, welches sehr grob und auch ein bisschen vage oder schwammig die vorstellungen von der private cloud skizziert, beschäftigt sich mit den verschieden modulen. diese sind vorläufig mit
1. frontend
2. backend/datamodell
3. cluster
4. mechanics
5. cdn
umrissen. das frontend soll schlank sein und möglichst in einem rutsch, in einer datei ausgeliefert werden. da dynamische anfragen an die cloud möglichst minimal gehalten werden sollen, ist die anlieferung der inhalte – wenn statisch – dann durch einige cache-layer abgefedert. da die dateien auf verschiedenen knoten verteilt sind, kann es bei ungecachten dateien durchaus 2-3 sekunden dauern, bis diese verfügbar sind. ein prefetch oder precache ist daher sinnvoll. die dynamischen inhalten werden durch ein nosqlschema realisiert. das datenmodell ist in verschiedenen schichten sowohl im front- als auch im backend nutzbar und ist teilweise durch generische klassen oder reflektive methoden ergänzt. die dateiablage kann man als flatfile ansehen, die durch map-reduce-aufbau oder ein denormalisiertes modell gekennzeichnet ist.
was heute cloud heißt, war vorher ein cluster, davor ein grid und irgendwann bestimmt auch mal ein mainframe 🙂 die heut noch üblichen architekturen, mit application-server <-> database-server, network-attached-storage und ftp-backup wird verglichen mit dem konzept, welches meiner entwicklung zu grunde liegt. die skalierung von 6-10 maschinen ist dort skizziert, die 5.000 maschinen, die bei hadoop-clustern durchaus üblich sind, muss sich der geneigte leser dann vorerst doch noch vorstellen.
der workflow oder die sequenzen, die für die arbeit zwischen den layern benötigt wird, kann man als mechanik in diagrammen aufzeigen, so können für verschiedene anwendungszenarien die beteiligten komponenten identifiziert, beschrieben und ausgebaut werden. da alles in einer sprache verfasst ist, ist ein medienbruch oder andere dialekte vorerst nicht nötig.
ist die orchestration dann über verschiedene kontinente und mehrere rechenzentren verteilt, so können funktionen eines cdn implementiert werden. dort werden dann ungesehener und gesehener inhalt ausgetauscht, statistiken für die optimierung und auswertung angelegt und die günstigsten, schnellsten oder besten routen für die anlieferung der daten gewählt.
mit dieser infrastruktur kann dann auch streaming betrieben werden, da die signallaufzeiten und die kapazitäten den anforderungen des marktes angepasst sind und entsprechend flexibel dimensionierbar sind.
das projekt der private cloud den menschen zu vermitteln und dann noch zu erklären, dass man damit seine freizeit gestaltet, ist mir über die jahre nicht einfacher gefallen.
der begriff „eisenbahnplatte“ trifft vermutlich noch am ehesten dass, was otto normal bereits von anderen kennt, wenn es um viel arbeit, geld und liebe geht, das in ein projekt fließt, welches vermutlich nie wirtschaftlichen bedingungen unterworfen ist. man könnte es auch luxus nennen oder wie es allgemein genannt wird: hobby.
da ich mich nicht nur auf arbyte, sondern auch am wochenende oder nach feierabend mit den themen hier beschäftige, sah ich diesen begriff noch am dichtesten an dem, was eh schwer zu beschreiben ist. da dazu jede menge programmierung gehört, die erst gut läuft, wenn die konfiguration ein mindestmaß erreicht hat, ist die komplexität in zusammenhang mit der hardware und den modulen, die extern verwendet werden immens. ich hab garnicht präzise vor augen, wie viele schichten / layer nun tatsächlich involviert sind, manche sind absichtlich eingezogen, um module zu entkoppeln, andere lassen sich vielleicht auch reduzieren und einsparen.
da mir in den verschiedenen phasen schon beinahe der kopf geplatzt ist, hab ich teilweise oder an bestimmten punkten, die arbeit ruhen lassen und dinge aufgemalt, beschrieben oder sonstwie umrißen oder skizziert, damit nicht nur ich die dinge verstehe, sondern eben auch andere.
daher ist die eisenbahnplatte all das, wozu ich nach dem 3. oder 5. mal keine lust oder kraft hab, es zu schildern oder zu erklärbärn. daher auch der blog hier, um einsicht zu schaffen und ansichten zu vermitteln, die aussenstehenden oder interessierten die möglichkeit gibt, dinge zu erfahren, die sonst nur schwer oder schwierig zu erfassen oder gar zu finden sind.
„die eisenbahnplatte fuhr schonmal“ mit drei nodes, doch sind mittlerweile alle server vom netz und derzeit wird neue hardware getestet und konfiguriert, damit der wirtschaftliche aspekt nicht zu kurz kommt.
as i have the rootServer, i can try and play niceley with my own coded stuff in java, running on tomcat. as the default-webserver just having the php stuff on it, i was looking for my own machine ( or at least for the chance to deploy my stuff ) since a long time.
with no big experience in the hosting field, iam not sure to put the tomcat naked onto the web, so i decide to hide the service behind a proxy/router. after i looked into the given examples, apache could be used therefore. thats to easy, i thought and i remembered some lighthttpd from my school, that one professor took for his page.
configuring the ports and the reverse-proxy was done quite quick, but having more then one subdomain means more then a single config-file. another thing is, that i want to play with load-balancing, so the config was done in three parts. as example, the workflow of a domain like reporteer.ioioioio.eu
part 1:
reporteer.ioioioio.eu to localhost:80. the gateway with round-robbinload-balancing on a virtual host (server-0) in berlin and redirect to the server-1 in jena.
part 2:
redirect from port 80 on server-0 to server-1 port 80, where another lighty was running.
part 3:
redirect from port 80 to port 8080, where tomcat was running and targeting the servlet-path like http://server1:8080/reporteer/
caching on each layer for different filesizes and different file-types was done that way. as the commong filesize on the http level is mostly below 64 kilobyte ( to measure ) i passed files from the servlet between 64kb and 1mb as java-cache, smaller files on the lighty-instances, separated for images and js/css. so, some css and some javascript ( lets say up to 8 ) per request was reasonable. a unbounded amount of images where handled by the servlet, beside tiny pictures, like thumbnails and icons.
so i felt a bit save for my tomcat, that exploits or my shity code wont run into a desaster for external incomming requests on port 80. „the evil hacker“, who wanted to get inside the machine would have to overcome the multiple redirect-layers on the plain/vanilla web-server, to catch the tomcat. beside the fact, that i didnt used any php/cgi nor sql-engine, the chance to fail to quick was not my point anymore.
but the main aspect is, that i can run active code now on the machine. before that, i just made passive / xml based stuff with gwt to run on the vhost i had. now remote-procedure-calls ( rpc ) are possible, beside general httpRequest.