
while we went warm with theoretical package dense of up to 8x nodes in 1he server case, the reality is comming by and tell us, what is really up to do. the given hardware is:
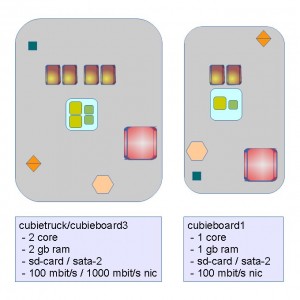
- 1x cubieboard1 | 1 hdd 500 gb
- 1x cubieboard3 | 1 hdd 2 tb
2x + 1x
the price tag is 90 + 50 = 140 € for the boards alone, without any harddrive nor router nor accessoires. the money is allready spent to the development god of tiny devices with giant duties. it could handle 100 mbit/s to the outside world, or with some usb-ethernet–adapter possible the 1000 mbit/s from the bigger one, but on some point, the conversion/transversion from gigabit ethernet to 100 mbit/s must be done. the best way would be a board with dual-network-connector, but its not available yet.
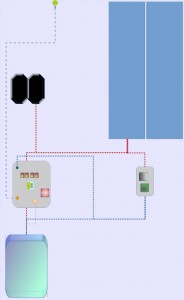
- 1x cubieboard3
- 1x 2 core
- 1x 1 gb ram
- 1x 100 mbit/s / 1000 mbit/s nic
- 1x 500 gb / 2 tb hdd
- replication factor 1
- price: 1 board + 1 hdd = 90 € + 90 € = 180 €
node config 2X
thats the current state. as the network extension cable is not working well, as we tried to wire the two leds for connection and traffic to the outside world. so the 100 mbit/s / 1000 mbit/s version is ready to gamble, but just with a replication factor of 1. thats poor, that less then raid 1 to compare it a bit. the harddrive should never fail or the backup for 500 gb is able to sync. within 24 hours on dsl-speed, at home. two fans should be ok for that amount of power consumption.
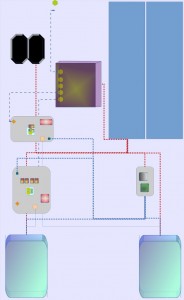
- 1x cubieboard1 + 1x cubieboard3
- 1x 1 core + 1x 2 core = 3 core
- 1x 2gb ram + 1x 1 gb ram = 3 gb ram
- 1x 100 mbit/s / 1000 mbit/s + 1x 100 mbit/s nic = 200 mbit/s
- 1x 2 tb hdd + 1x 500 gb hdd = 500 + 1500 gb hdd
- replication factor 2
- price: 2 board + 2 hdd = 90 € + 50 € + 2x 90 € = 320 €
node config 2X + 1X
here is the configuration with the available boards that i have for now. line speed is like the same, as above, the logical bandwith would be 200 mbit/s if duplex is working without a loss. nothing needs to be shoped, all visible parts are on stack. screwing that into the case is another step, but then the system should run, even if on harddrive fails. a internal router is needed, 3 ports would be fine for that. another way is, to connect the smaller load-balancer bord with a usb-ethernet-converter, but thats mystery from here on, as not every library is compiled on armhf. the power conversion needs to be doubled 4 ampere should be available for both boards.
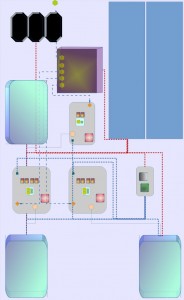
- 1x cubieboard1 + 2x cubieboard3
- 1x 1 core + 2x 2 core = 5 core
- 1x 1gb ram + 2x 2 gb ram = 5 gb ram
- 1x 100 mbit/s + 2x 100 mbit/s / 1000 mbit/s nic
= 300 mbit/s + 1800 mbit/s - 3x 2 tb hdd
- replication factor 3
- price: 3 board + 2 hdd = 2x 90 € + 50 € + 3x 90 € = 500 €
node config 2 x 2X + 1X
here is a version with a configuration of smooth compaction. logical bandwith would be 300 mbit/s or 2 x 1000 mbit/s + 100 mbit/s if the adapter is willing to switch it that way. another chance is a router, with a uplink, which handle that multiplex shifting. replication would be the minimum, as suggested. a internal router is needed, 4 or 5 ports would be fine for that. the power conversion needs more attention, estimated 6 ampere should be available therefore. three fans will blow the heat of the discs away, beside the little temperature fom the tiny boards.
its hard to find a conclusion on that. one the one hand 320 € are allready spent, with harddrives and that two boards. the actual configuration costs around 180 €, but upgrading to the goal of replication factor 3, is another 180 € away. were in the middle of that price tag.
okay, the cheapest entry class server on dells online shop starts around 600 € for 2 core, 4 gb ram. for 745 € we could get 4 core and 8 gb ram, just to have more blast. to get replication 3, we need to spend another 400 € for additional sas-drives, makes it to 999 €, with the 2c / 4gb configuration. having more cpu and three drives, the price would be 1145 €. thats twice of our diy cloud-node and the example case to show up with.
we could have replication factor 3, but a quarter of cpu power available, compared to a pentium-class or xeon-based server with replication factor 1. having replication factor 3 there, with the bottleneck of a single board.
the independent boards could be configured via software as needed. thats called software-defined-network ( SDN ) nowadays. the single server board will be rougher as a developer board, but that would just be one node, with a unstriped disc-array. the cubie´s would present 3 nodes, for half the price, with a estimated four to six times slower arm v7 cpu. using the gpu with software will take another 1 or 2 year, from now on – if happen anywhere.
so, bringing it online the described upgrade way, would save the money to the point, when replication of 3 is urgently needed or when another chasis/case is ready to be deployed. then, the 2 + 3 drives would make the boom, the system is going to present for that issues.
serving web content is one case for that system. handling large files as no-sql engine, filebased with some glue, is the main goal within the logical network layer. synchronizing a database-cluster on one master and two slaves, would lower the bandwith for the need of replication. that will just scale between 2-5 or so. the distributed system would level that above 3 boards, in one server-chasis.
the network behaviour is not counted in this mind construct, a layer-3-switch would be very gentle to the paket-flow, but is outside the budget nor tested at all. switching the 5 – 8 available ports with 10 gbps would be fair enough, then the machine would have 1.5 gbyte/s inner bandwith, makes it half a iscsi device, targeted with single connect on 4 gbps.

